關於 TDD (Test-Driven Development)
- Red, green, refactor cycle
- 預想好使用情境
- 一次只會專注一個目標,一次解決一個問題
- 避免過度設計
Mindset:設計決策一次只聚焦在一個地方
好好評估環境適不適合TDD(連需求都不確定時,不建議使用TDD)
關於命名
我們在開發程式的時候,都是 “read lines randomly” 的,不像電腦會逐行讀取。Making wrong code look wrong - Joel on software
Maintainability
用人讀 code 的方式來定義 MaintainabilityTo understand a random line, the lines you need to read back.相對於programmer的時間,運算資源比較不值錢。
把時間專注於想要做的事情,而不是 debug 上面。
Boost Maintainability
- Define our “Maintainability”
- Making it zero
- progressive from zero
Maintainability
Be exact & consistent (命名要精準且有一致性)舉個例子
result = ...
result = ...
命名的好方法
常常用 dictionary,對一個領域不熟悉的話可以多查字典來找到更好的名字哦!Ops Hint
命名具有提示的作用,提示有怎樣的operation可以用page_no = ...
page_html = ...
page_no 是一個數字,而 page_html 是一個字串allowed_field_set = set(requested_field)
consistent問題
用d來標示dictionaryuser = User(...)
user_d = {}
Hint: func 的命名如果沒有取名好,那發現問題還需要查 document,這個更耗時不要把
建議:func都用動詞開頭,就會記得加上()
is_secure = True 與 req.is_secure() 混用以
形容詞、介係詞 來當 boolean 會比較好或者用簡單的句子來表示 boolean:
req_is_secure = TrueOps Hint (Mosky 使用的習慣)
- Hint which ops you should use
- _no: numeric
- <plural>: sequence, usually is mutable sequence(list).
- _<type>: if no intuitive way
- (這邊好像有缺漏,求有筆記到的幫補充)
- <verb>_: imperative sentence
- <yes-no question>: return boolean
- to_<thing>: thing
- boolean: <adj>, <prep>, <simple sentence>
return value
- get_page_no -> numeric >= 1
- query_user -> user object
- parse_to_tree -> tree object
avoid None
Consider:
user = query_user(uid)
user.is_valid()
Accept an exception ?
- N: user dummy object like an empty string.
- Y: just raise when you wanna assign to None.
如果沒有檢查好做好處理
tmpl = '<p>{}</p>'.format(name)
name = '<script> ... </script>'
#XSS
tmpl_html = ... .format(
escape_to_html(name)
)
Structure Hint
uid_email_map = {
'mosky': 'mosky@email'
}
for dict & tuple
- <key>_<value>_map
- tuple
- _pair: 2-tuple
- _pairs: 3-tuple
Private Hint
- _<name>
- Dont use out of class, function
Performance Hint
- get: memory op (記憶體的操作)
- parse_ / cale_: CPU-bound op
- query_ : IO-bound op
- query_or_get_: IO-bound op with cache
Progressive from zero
- 不要自己自創縮寫,可以去網站上查
- 如果只是要在一個 func 裡面用而已,可以用註解來解釋縮寫定義
(目前著重於讓人能夠更快讀懂 code,所以才這樣說) - 把程式分段跟分節
- 把做一系列事情的分段及分節
- 用
空行來把不同的事情分隔開 - 用
section的方式來切開(Title comment 來區隔開不同的區塊)
Line Function up(把程式連線起來)
Func A call Func U, Func B call Func U可以從連線的方式來慢慢切開變成函式的模組化
Hint: 最好把箭頭指向的方向全統一到同個方向
Face Bad Smell(察覺程式碼中的壞東西)
不要為了克服心理上的潔癖而造成開發上時間的損失
就是不要因為覺得 code 很醜就浪費一下午改好又不能動 XD
- 用 comment 來解決痛點而不是改寫
- 放很多 TODO,不是不改是時候未到 XD
- Seal it:把他封起來就對了,或是用更好的名稱把他包起來
- def good_name(): bad_name()
- Stay focused:認真寫 code,舊的東西先放著!
關於Immutable infrastructure
- 不是修改原有的,而是當有更動時,就做一個新的
- system infrasturcture =
data+other other是要被版本控制的,每次發布都會被覆蓋掉的
-
壞處
- 每一次更動都會是一個新的 image ,作 image 是有時間成本的
-
OpenStack
- 整合運算資源、網路資源、儲存資源
- 依賴KVM
- 新版Docker允許將OpenStack封裝在裏面
-
Docker
- not a hypervisor, a container on kernel
-
Ansible
- interpret, deployment tool, written in python
- use YAML
-
OpenStack Kolla
- docker + ansible to deploy openstack
關於Pandas
- pandas :處理文字數值型,屬於 python 的高階處理方式
- GeoPandas :處理地理資料(空間資料、屬性資料等)
- GeoPandas 比 Pandas 多了可以處理地理資料的功能
- 分析地理資料前先要了解坐標參考系統 CRS
- 目前拿到的大部分都是 TWD97 資料,因為921地震後有重新做過地面測量
- 利用空間關係做資料的join (geopandas 用
sjoin)
關於Deep Learning
-
Information Retrieval System
- Query
- Encoding
- Database Matching
- Ranking
-
資料前處理套件
- pandas
- numpy
-
Machine Learning 套件
- xgboost
- scikit-learn
-
Deep Learning 的套件:
- theano
- lasagne
-
Convolution
- 目的:利用translation invariant 的特性來增加準確度
-
Subsampling
- 壓縮資料,並且壓縮後的資料不失真(保有特徵)
- 降低資料緯度來減少運算資源
-
PS:更精確的convlution 和 maxpooling 可以參考李宏毅教授這份 投影片裡面對應到的CNN解說 (by CHLin)
-
Feature Vector
- Feature Extractor 非常重要,產生的 feature vector 會影響最終結果
- 主要用途為代表原本輸入的特徵值
- 經由多層的convolution and subsampling達成
-
Sentence Retrieval
- 先定義短句的長度
- 如果長度太短,加上 padding,這樣才有辦法處理
- 用 PCA 降維(feature vector),再用 tSNE map 到2維
-
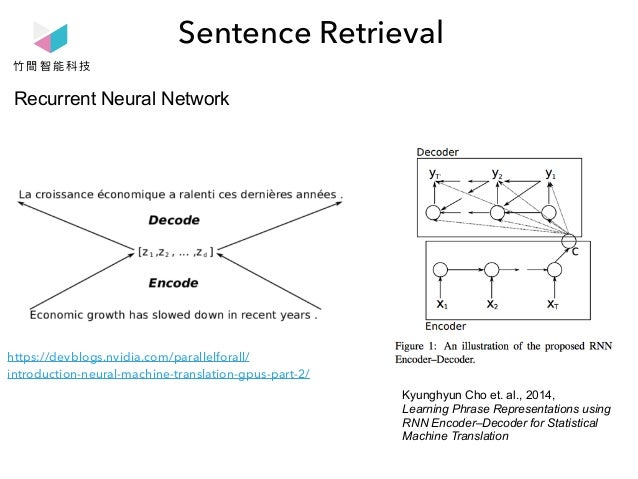
Recurrent Neural Network
- 將英文encode成feature vector,再將feature vector decode成法文
-
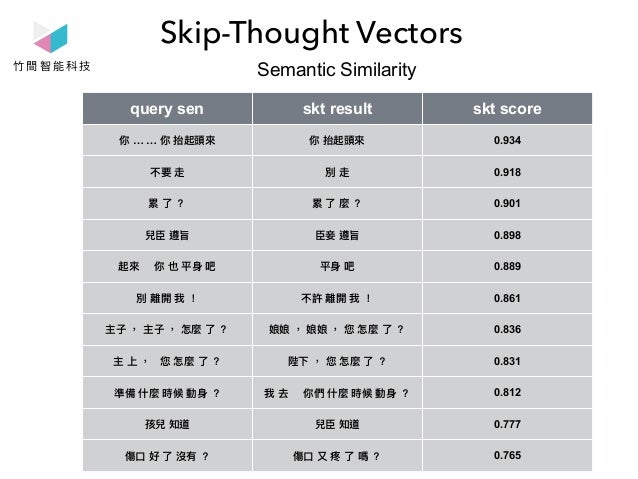
Skip-Thought Vector
- 缺點:
- 需要非常大量的資料
- Scenario dependency
-
Image Retrieval
- 參考 Deep Learning of Binary Hash Codes for Fast Image Retrieval
- 通常作法:找別人train好的model,再去fine tune
沒有留言:
張貼留言